The different sources of data that can be used for machine learning applied to chemistry and materials R&D
Machine learning is a powerful tool to accelerate chemistry and material science R&D as it allows to find hidden trends in data, making it possible to predict the outcome of experiments or to suggest experiments to achieve an objective (for example, maximizing the yield of a synthesis). When considering using machine learning for chemistry or material science R&D, one of the first questions to be asked is: What data can be used and should be used?
For chemistry and material science, data is available from various sources:
- Project-oriented datasets,
- Company or laboratory databases,
- Data from publications,
- Public databases,
- Data from simulations.
The purpose of this article is to give an overview of these sources in order to help chemists and material scientists select the right data source(s) for their problem.
Selecting the right data source(s)
When selecting data source(s) for machine learning, four questions should be asked:
- How easy is it to standardize the data?
The data used in machine learning projects needs to be standardized, meaning that all the entries in a dataset need to have the same structure. If there are missing measurements in some experiments, these measurements can be left blank to keep a common structure. Some sources contain already standardized data while others require standardization work to be usable for machine learning. - How many data entries can this data source provide?
For a machine learning project, the required quantity of data entries increases with the complexity of the problem to solve. For example, this complexity depends on the number of variables in the experiments, on the correlations between these variables and on the complexity of the chemical and physical phenomena involved. It is not possible to know the number of entries needed for a machine learning project from the beginning; your only option is to train a machine learning model with the initial dataset, assess the accuracy of the obtained model and decide if more data is needed in order to improve the model. - How diverse is the data?
The diversity of the data is linked to how different each experiment is from the other experiments of the dataset. In other terms, the diversity depends on how well-spread are the experiments in the experimental space. The more diverse is the data given to a machine learning algorithm, the more information the algorithm disposes to learn from and the better the algorithm will be at generalizing its predictions. - How convenient is it to access the data?
When building a dataset for machine learning, the time and money needed to extract the data varies from one source to another. Some sources are not free to use such as publications while some sources require a lot of effort to gather the data such as lab notebooks that needs to be inputted in datasets.
Project-oriented datasets
A project-oriented dataset is a dataset created specifically for one or several machine learning projects. The data is usually gathered from projects conducted within one company or laboratory, thus the experimental conditions are probably well-known, making the data reliability easier to assess than for data acquired from external sources.
On the other hand, this source might not provide enough information to train a machine learning model with the desired accuracy. There may not be enough data available, or it can be too complicated to retrieve the data (for example, when it is stored in old lab notebooks or excel files that are missing informations).
When new experiments need to be performed, active learning can be used to speed up the process. Active learning is a method that allows researchers to reduce the number of experiments needed to achieve a given objective (for example, maximizing the corrosion resistance of an alloy or reducing process waste). As shown in Illustration 1, the algorithm is trained with the existing data and given optimization objectives. Then the algorithm suggests experiments with combinations of parameters which are the most likely to reach the optimization objective. The new experiments are performed and the results are then added to the data. This process is repeated until the objective is reached.
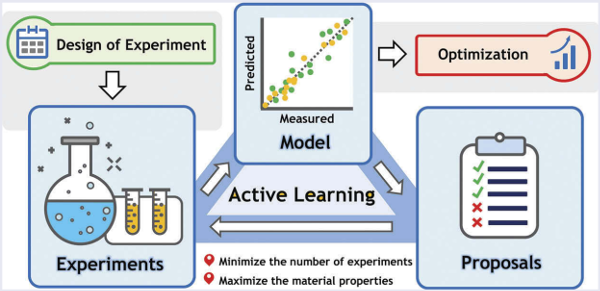
Illustration 1: Fundamentals of working with active learning algorithms for material science.
The article "Prediction and optimization of epoxy adhesive strength from a small dataset through active learning" is a good example of the use of active learning with a small dataset. Pruksawan et al. wanted to predict and optimize the strength of an epoxy adhesive. They started by training a gradient boosting algorithm with their own experimental data (32 experiments). They used this algorithm to predict the adhesive strength of 224 epoxy adhesive compositions and prepared the 5 compositions with the best predicted results. They then trained the algorithm again with their new experimental results. They repeated this process 3 times, until the algorithm predictions were considered accurate enough. The algorithm was able to predict the strength of epoxy-adhesives (σad) with a reasonable precision (R2 > 0.80) for such a small dataset (47 experiments in total). Finally, they performed three more iterations of active learning with a Bayesian algorithm. The Bayesian algorithm coupled with active learning allowed to optimize σad to 35.8 MPa when the maximum value that was obtained previously was 31.9 MPa. Below is the framework they used to work with active learning.
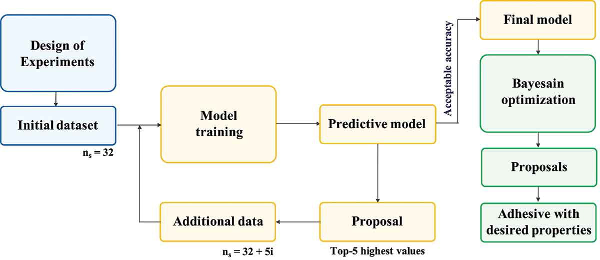
Illustration 2: Framework for working with small datasets and active learning.
Company or laboratory databases
A database is a collection of standardized data with a common subject. The objective of creating a database is to provide a lasting source of data that can be be enriched over time and be used for various projects. As a database is standardized, it is generally fast to create datasets for machine learning from databases. For example, a company or laboratory performing polyamide syntheses can regroup all these synthesis results in a database and use this database to train machine learning models (for example, to predict bio-sourced polyamide syntheses).
Interestingly, company databases are likely to include the experiments that did not give the expected results, which are often missing in scientific articles. This increases the diversity of the data and allows to build more accurate machine learning models. Moreover, it is generally easier to assess the reliability of this data source compared to public databases or publications.
On the other hand, gathering data for creating a database can be laborious when it needs to be recovered from old lab notebooks or excel files, which are not always well organized.
A successful example of research using a laboratory database can be found in the article: "Machine-learning-assisted materials discovery using failed experiments". Raccuglia et al. used 4000 experiments previously performed in their laboratory to predict the outcome of vanadium selenite syntheses. They recovered the experiments, including failed ones, from old lab notebooks and included physiochemicals properties of the organic and oxalate-like reactants. After training a predictive algorithm with this database, the algorithm was able to predict the outcome of vanadium selenite syntheses from new diamines with a higher success rate than an experienced researcher (89% vs. 78%). Below is a diagram that summarizes the methodology they used.
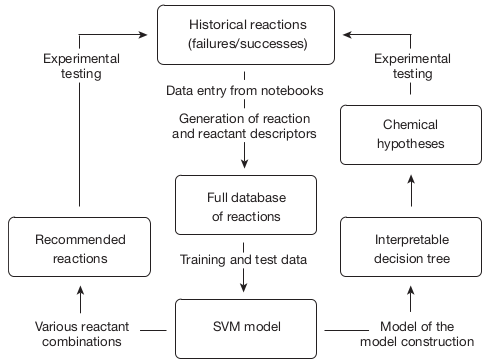
Illustration 3: Example of a framework that can be used while working with a company database.
Data from publications
Data from publications can be used to create a dataset or expand an existing one without performing any experiments. Each article can increase the diversity and quantity of data in the dataset, thus improving the generalization ability of a machine learning algorithm trained from the dataset.
On the other hand, the main disadvantage of this data source is that it is hard to assess the reliability of the data. Another disadvantage is the difficulty of extracting the data; if you use several publications, the data is likely to be formatted differently in each publication. Therefore, the data needs to be extracted independently from each publication. The extracted data then needs to be standardized as, from one publication to another, the types of measurements and how they were performed are likely to be different.
Very often, the published data do not include all the failed experiments from the project and therefore the created dataset may lack balance between failed and successful experiments. This lack of balance can reduce the prediction efficiency of the machine learning algorithm by creating learning biases. Such biases can result from a ratio between failed and successful experiments in the publication that doesn’t reflect the ratio between failed and successful experiments in the project. For example, when building a machine learning model to predict the outcome of a synthesis, the training dataset should include failed syntheses, otherwise the algorithm won’t be able to predict accurately if a synthesis is going to fail or succeed.
An example of work conducted by using data from publications is "Accelerated discovery of metallic glasses through iteration of machine learning and high-throughput experiments". Ren et al. started by gathering 6780 results of metallic glass synthesis attempts that they found in scientific articles from the last 50 years. This dataset was used to train a machine learning algorithm that they called the "1st generation algorithm". They then selected the ternary with the highest predicted probability of containing metallic glasses and performed experiments in this ternary. These experiments confirmed that this ternary contained metallic glasses in zones similar as the ones that were predicted by the algorithm. The experiments were then used to train a 2nd generation algorithm. A second iteration of this process was performed an yielded a 3rd generation algorithm.
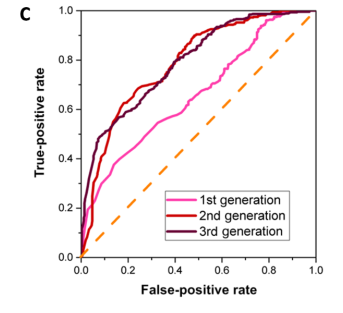
Illustration 4: Comparison of the 3 generations of models.
In Illustration 4, we can notice that the accuracy of the model increases sharply between the 1st and 2nd generation. This is due to the fact that, contrary to the literature data used for the 1st generation, the data added for the 2nd generation contained experiments with failed synthesis attempts (a crystalline material was obtained instead of a glassy material). This shows the bias that can result from the lack of negative results in the literature data. Finally, the authors estimated that the 3rd generation algorithm precision was sufficient for their research. They also estimated that using this method made their discoveries 200 times faster than before!
Public databases
Public databases can provide large quantities of data to use in machine learning projects. Here are some examples of open access databases that can be used for R&D:
- The Crystallography Open Database which provides 453 705 entries of crystal structures of organic, inorganic, metal-organics compounds and minerals, excluding bio-polymers.
- The Materials Data Facility where you can find material science datasets with more than 45 Terabytes of data.
- The Organic Materials Database is an electronic structure database for 3D organic crystals with around 24 000 material entries.
In a database, the data is standardized, making the data fit for use in machine learning. However, if a database is used with other sources of data, the data will need to be restructured to fit a common structure. Some methods exists that can help gathering data from databases and re-structure it, as presented in the research article "A new semi-automated workflow for chemical data retrieval and quality checking for modeling applications". Gadaleta et al. needed to gather data from 3 databases that were using different molecular descriptors. They provided a workflow to optimize data gathering from 3 open access databases for QSAR modeling. Thanks to this workflow, they successfully built a database with standardized molecules descriptors that can be used for QSAR modeling.
An interesting example of the use of public databases for chemistry can be found in the article "Using Machine Learning To Predict Suitable Conditions for Organic Reactions". Gao et al. designed a hierarchical neural network and trained it on 10 million organic reactions extracted from the Reaxys database (a commercial database). Their objective was to predict suitable conditions for organic reactions. They then tested the accuracy of the model with 1 million reactions from the same database that were not used to train the algorithm. For each reaction, they compared the top-10 predictions from the model to the reported conditions from the database. For 70% of the tests, the algorithm was able to correctly predict the temperature (±20°C), reagents (up to two), solvents (up to two) and catalysts. As the model was trained with a huge amount of data, it proved more effective than previous ones for generalization.
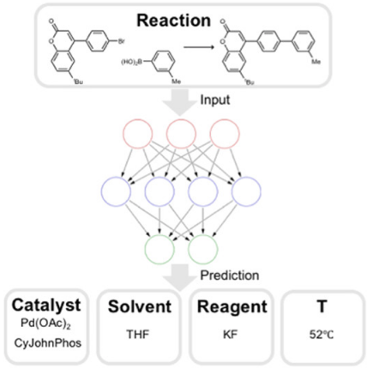
Illustration 5: Using neural networks to predict reaction conditions with the Reaxys database.
Data from simulations
When there is no data available, simulations allow to build a dataset without performing experiments. For example, hazardous or expensive experiments or experiments producing polluting substances can be avoided by using simulations.
When considering using simulations to build a dataset, two important concerns are the money and time needed to perform simulations accurate enough for the research problem. Simulations for chemistry and material science can require long calculation times and need expensive servers therefore performing experiments can sometimes be cheaper than performing simulations.
The Open Quantum Materials Database is an example of a public database of simulation results, which regroups DFT-calculated thermodynamics and structural properties of inorganic crystals.
In the article "Deep-learning-based inverse design model for intelligent discovery of organic molecules". Kim et al. assembled a database of 6000 molecules possessing a DFT-calculated triplet state energy higher than 3.0 eV. They trained a deep learning algorithm with this database to automatically design organic molecules with targeted light absorption properties to create phosphorescent organic light-emitting diodes. The deep learning algorithm was separated in three parts: a random molecular fingerprint generator (a molecular fingerprint is a series of digit encoding the structure of a molecule), a deep neural network (predicting the triplet state energy of the molecular fingerprint) and a recurrent neural network (decoding the output of the deep neural network and translating it to SMILES codes representing the molecular structure). After training, the algorithm was able to propose 3205 molecular candidates and predict their triple state energies. The figure below displays 9 molecular candidates and their triple state energies predicted by the model and calculated by DFT. This study proved the efficiency of using simulations to create large datasets for machine learning.
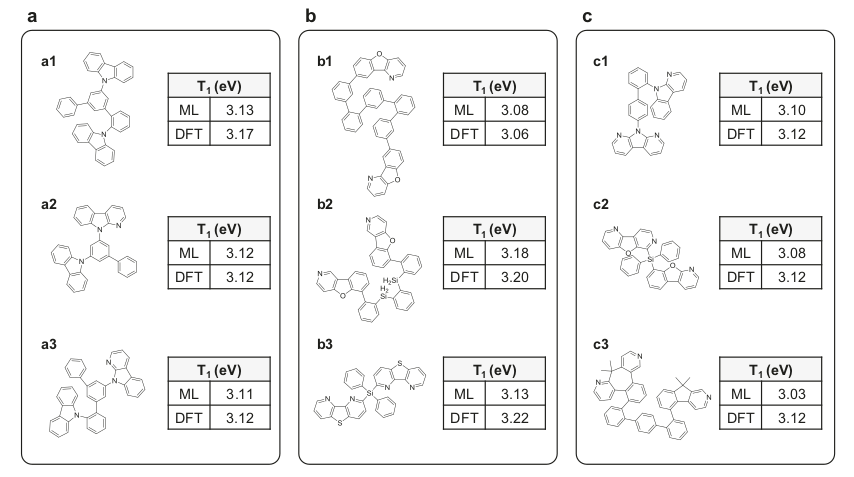
Illustration 6: Molecular candidates and their triple state energies calculated by Machine Learning (ML) and DFT simulations. (a: Asymmetric molecules constituted of fragments that were already present in the training library, but that are now assembled in a different way; b: Symmetric molecules containing at least one fragment which was not present in the training library; c: Asymmetric molecules containing at least one fragment which was not present in the training library).
Conclusion
Assembling a dataset is one of the first steps of a machine learning project. In chemistry and material science, data can be available from 5 different sources: project-oriented datasets, company databases, data from publications, public databases and data from simulations.
When choosing data sources, you should look upon the following criteria: the ease of access to the data, the possibility to standardize it and to assess its reliability and the quantity and diversity of the data. All sources have benefits and drawbacks so compromises must often be made.
Sometimes, there is not enough data available to train an efficient machine learning algorithm. To complete the data, new experiments can be performed using an active learning approach or simulations can be performed.