Accelerated discovery of metallic glasses through iteration of machine learning and high-throughput experiments
Metallic glasses are amorphous alloys of metals and metalloids. They usually have properties that are very different from crystalline alloys: exceptional mechanical performances (eg. yield strength and wear resistance) and sometimes improved corrosion resistance or high magnetic permeability.
Finding new metallic glasses means finding right combinations of several metals and metalloids, in the right proportions, and using the right experimental procedures. This task is very difficult, even for domain specialists, and requires a tremendous experimental effort. The first reason for this difficulty is that the search space is huge: there are hundreds of possible combinations of metals or metalloids, in any proportions, and there are different experimental procedures than can be used to combine these elements. The second reason is that there is no satisfying physico-chemical theory that is able to predict if a given composition will give a glass or a crystalline material. Thus, scientists rely on their experience, their intuition, some (unsatisfying) physico-chemical theories and a lot of trial-and-error experiments.
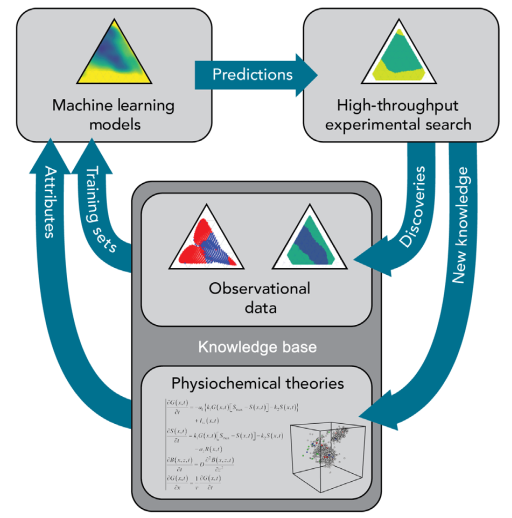
In the article "Accelerated discovery of metallic glasses through iteration of machine learning and high-throughput experiments" (Sci. Adv. 2018; 4:eaaq1566), Ren et al. used a combination of high-throughput experimentation and machine learning modelization to greatly accelerate the discovery of new metallic glasses. As presented in the following scheme, machine learning was used to predict if given alloy compositions had high probabilities of giving glasses or not. These machine learning predictions were then used to select metal combinations to be tested experimentally. High throughput experiments were performed to confirm which compositions gave glasses, and the results of these experiments were fed to the machine learning algorithm so that it could continue to learn. This iterative approach allowed to improve over time the predictions of the machine learning program.
The authors limited their study to ternary alloys. They started by gathering 6780 results of metallic glass synthesis attempts that they found in scientific articles from the last 50 years. These literature experiments used 51 different metals and metalloids. This dataset was used to train a first-generation machine learning model using the Random Forest algorithm. If you want to learn the basics of the Random Forest algorithm, we recommend these two didactic (and slightly humoristic) videos on the subject:
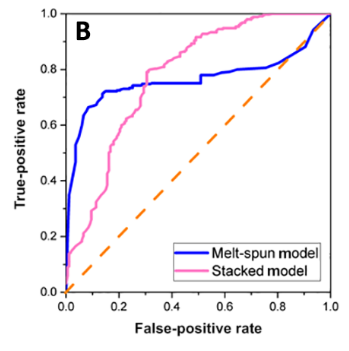
This first-generation model, trained on literature data, was then evaluated with a cross-validation test to determine its ability to make predictions on ternaries that were absent from the training dataset. The reciever operating characteristic (ROC) curve of the model is presented below. Without going into the details of the blue and pink curves, we observe that the curves are significantly far from the orange dashed diagonal, which indicates a rather high classification performance (the closer the curve is to the top left corner, the higher the classification performance).
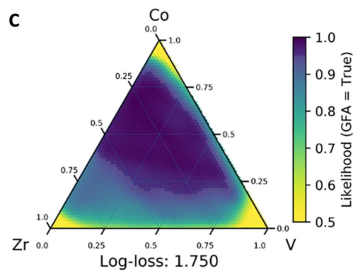
The following figure shows the ternary which had the highest predicted probability of containing metallic glasses: the Co-V-Zr ternary (blue regions have a high predicted probability of being amorphous).
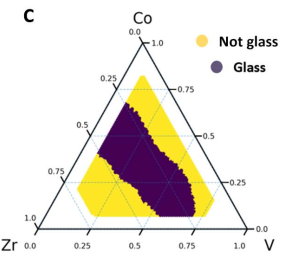
The authors selected this ternary to perform the first high-throughput experiments. As we can see in the figure below, the experimental results (purple region = glasses) confirmed that this ternary contained a large proportion of compositions that led to glassy materials.
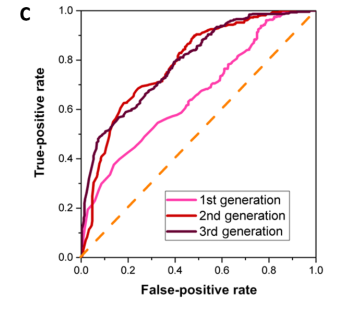
These experimental results were then used to continue the training of the random forest algorithm, which led to a second-generation model. The reciever operating characteristic curves for the first-, second- and third-generation (which was obtained after other experiments) machine learning models are presented below. Between the first- and second-generation model, there is a significant increase in prediction accuracy (the curve gets closer to the top left corner). The authors explain this by the fact that the experimental results contain both positive (glassy materials) and negative (crystalline materials) results, contrary to the literature data, which is biased towards positive examples. This better balance between positive and negative examples helps the machine learning algorithm learn to distinguish between compositions that give amorphous or crystalline materials.
This article is an excellent application of machine learning techniques to a materials discovery problem that is too complex to be solved by the human intuition alone and for which there exists no satisfying physico-chemical theory to make accurate predictions. Even with a relatively small starting dataset (less than 7000 examples), the authors succeded in making initial predictions that were sufficiently accurate to guide high-throughput experimentations, which results were then used to refine the machine learning model to make more accurate predictions. The authors estimated that their new methodology allowed them to discover new metallic glasses 200 times faster than was possible before!